Hi,
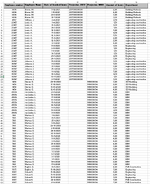
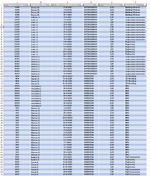
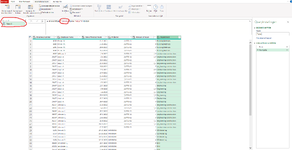
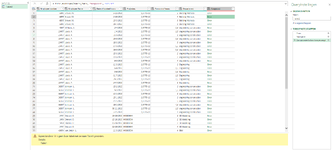
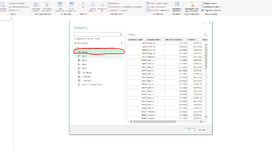
I have a dataset with the hours spent on different projects over the years 2020 and 2022 (about 150000 rows of data). The hours are tied to a person and each person is tied to a department. The columns of each row contain: a specific project number (two types of projectnumbers one start with 2877 and the other with M000), the persons name who has booked his hours on the project, the amount of hours the person has booked and to which department this person belongs.
I want to know wich combinations of departments within the projects occur the most and which the least (something like 10 most and 10 least), so from the data you can see which person has worked on which project and because this person is also tied to a department it should be possible to find out which departments collaborate most and least on projects. Anyone have any idea how I can find this?
I have put a screenshot of the data.
I have a dataset with the hours spent on different projects over the years 2020 and 2022 (about 150000 rows of data). The hours are tied to a person and each person is tied to a department. The columns of each row contain: a specific project number (two types of projectnumbers one start with 2877 and the other with M000), the persons name who has booked his hours on the project, the amount of hours the person has booked and to which department this person belongs.
I want to know wich combinations of departments within the projects occur the most and which the least (something like 10 most and 10 least), so from the data you can see which person has worked on which project and because this person is also tied to a department it should be possible to find out which departments collaborate most and least on projects. Anyone have any idea how I can find this?
I have put a screenshot of the data.