I have been reading up on Normalization thanks to @Micron and the link to Roger's Access Blog: What Is Normalization, Part I
In this Blog about Primary Keys, he refers to Natural Keys and Surrogate Keys. I kind of understand this concept, but he doesn't give any examples that I can see implemented in Access of SQL, so I'm not sure that I understood the explanation fully. Natural Keys make sense to me because it makes use of a field that already exists. In my case, I'm building a database for Contacts and Opportunities, kind of like a Sales Funnel. None of my data inherently has a Natural Key, so I will be using a Surrogate Key - an artificially created number (Integer, Autonumber) - makes perfect sense. I now understand that I could create a Contact Entry for a person: PersonFirstName, PersonLastName, with the ContactID of "1", and then create another duplicate record for the same person with a ContactID of 10, for example. The database doesn't know that these are the same. Makes sense. That's one thing I want to avoid in my database design. So Roger says that one way to avoid that is by using an Index to "create a unique index on those fields that would otherwise create a natural key". I'm not sure what fields he's talking about. If I created the ContactID, that's my Surrogate Key, a.k.a. Primary Key. Why would the other fields constitute a Natural Key? I suppose, if I used his example, I could use FirstName/MiddleName/LastName to create a Natural Key/Primary Key, but then I still have the same duplication issue.
This is where Indexing comes in, as I'm learning.
 rogersaccessblog.blogspot.com
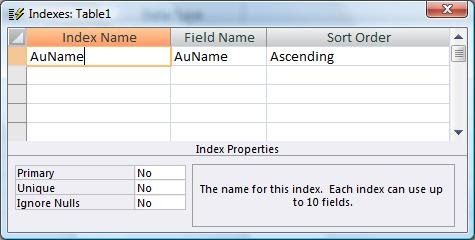
I understand the library cataloging reference that he uses to explain an Index, and I see how to create the Index. But I don't understand how to apply that to the Surrogate Key where duplicates are possible. Using the example above, suppose I mistakenly entered the same contact two different times so that I have two unique ContactIDs, but duplicate information in all the fields. How would I Index those fields to maintain uniqueness?
rogersaccessblog.blogspot.com
I understand the library cataloging reference that he uses to explain an Index, and I see how to create the Index. But I don't understand how to apply that to the Surrogate Key where duplicates are possible. Using the example above, suppose I mistakenly entered the same contact two different times so that I have two unique ContactIDs, but duplicate information in all the fields. How would I Index those fields to maintain uniqueness?
Thanks in advance for any guidance you can offer.
In this Blog about Primary Keys, he refers to Natural Keys and Surrogate Keys. I kind of understand this concept, but he doesn't give any examples that I can see implemented in Access of SQL, so I'm not sure that I understood the explanation fully. Natural Keys make sense to me because it makes use of a field that already exists. In my case, I'm building a database for Contacts and Opportunities, kind of like a Sales Funnel. None of my data inherently has a Natural Key, so I will be using a Surrogate Key - an artificially created number (Integer, Autonumber) - makes perfect sense. I now understand that I could create a Contact Entry for a person: PersonFirstName, PersonLastName, with the ContactID of "1", and then create another duplicate record for the same person with a ContactID of 10, for example. The database doesn't know that these are the same. Makes sense. That's one thing I want to avoid in my database design. So Roger says that one way to avoid that is by using an Index to "create a unique index on those fields that would otherwise create a natural key". I'm not sure what fields he's talking about. If I created the ContactID, that's my Surrogate Key, a.k.a. Primary Key. Why would the other fields constitute a Natural Key? I suppose, if I used his example, I could use FirstName/MiddleName/LastName to create a Natural Key/Primary Key, but then I still have the same duplication issue.
This is where Indexing comes in, as I'm learning.
Access 101: What is an Index?
Thoughts, opinions, samples, tips, and tricks about Microsoft Access
rogersaccessblog.blogspot.com
Thanks in advance for any guidance you can offer.
")



