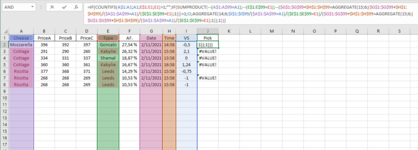
Hi everyone and thanks in advance for the help.
My main goal is to fill with formula the J column with the values of I column. With a few words if we don't have "duplicate rows" we just fill the J with the value of I. If we have "duplicate rows" (A and E are the basic criteria) we are looking at Date and Time and we pick the value from I according to date and time (if there is time difference we pick the the earliest) or (if they have same date and time) we pick the highest value.
The key is to fill with values the J column, according to the criteria of duplicate rows and Date Time.
Key columns and explanation:
Cheese and Type (A and E): With these two as a pair we are trying to find if there are duplicate values ("as rows") to the dataset A1:J8. For example: The Rows 3 and 5 are not similar (they have different values in most of the cells), BUT from the moment that the name of Column A3 (Cottage) and A5 (Kabylie) and E3 (Cottage) and E5 (Kabylie) are similar, for us are duplicate rows. In A4 we have a similar Value (Cottage) with A3 and A5, but the E4 is not the same, so they are not duplicates.
VS (I): This is the value that we must pick and send or not send to Pick if the criteria has been met.
Pick (J): Here is where we fill or not fill the value (we are taking this value from VS), if the criteria has been met.
Date and Time (G and H): If we have duplicate values (when they exist from the pair of Cheese and Type) we pick from VS the one which is the earliest, as you can see in J4 and we leave empty the other (J5). We have set as duplicates rows 3 and 5 because they have same name in column A and same name in column E, and we have picked the VS from I3, because row 3 has 15:58 time and row 5 has 16:58.
If we have duplicates and they have the same date and time (rows 6, 7, 8 are duplicates with same date and time) we pick the one with the highest value
If there are no duplicated values (like row 2 and row 4) we don't use this criteria. We just pick from VS the value and put it to Pick.
My main goal is to fill with formula the J column with the values of I column. With a few words if we don't have "duplicate rows" we just fill the J with the value of I. If we have "duplicate rows" (A and E are the basic criteria) we are looking at Date and Time and we pick the value from I according to date and time (if there is time difference we pick the the earliest) or (if they have same date and time) we pick the highest value.
| A | B | C | D | E | F | G | H | I | J | ||
| 1 | Cheese | PriceA | PriceB | PriceC | Type | AF. | Date | Time | VS | Pick | |
| 2 | Mozzarella | 396 | 392 | 397 | Goncalo | 27,54 % | 2/11/2021 | 14:58 | -0,5 | -0,5 | (it is not duplicate) |
| 3 | Cottage | 291 | 290 | 260 | Kabylie | 26,32 % | 2/11/2021 | 15:58 | 2,1 | 2,1 | (duplicate with row 5, but the time is earliest) |
| 4 | Cottage | 334 | 331 | 337 | Shamal | 18,87 % | 2/11/2021 | 13:58 | 0 | 0 | (not duplicate) |
| 5 | Cottage | 360 | 360 | 361 | Kabylie | 16,67 % | 2/11/2021 | 16:58 | 1,24 | (empty cell because it was duplicate with row 3 and the row 3 had earliest time) | |
| 6 | Ricotta | 377 | 368 | 371 | Leeds | 14,29 % | 2/11/2021 | 15:58 | -0,75 | -0,75 | (duplicate with rows 7 and 8, they had the same Time Date, BUT we have a value because this row had the highest value (from 0,75, -1, -1) of the specific cells in column I) |
| 7 | Ricotta | 268 | 268 | 269 | Leeds | 10,53 % | 2/11/2021 | 15:58 | -1 | (empty cell because it was duplicate with row 6, 8 and the row 6 had the highest value) | |
| 8 | Ricotta | 268 | 268 | 269 | Leeds | 10,53 % | 2/11/2021 | 15:58 | -1 | (empty cell because it was duplicate with row 6, 7 and the row 6 had the highest value) |
The key is to fill with values the J column, according to the criteria of duplicate rows and Date Time.
Key columns and explanation:
Cheese and Type (A and E): With these two as a pair we are trying to find if there are duplicate values ("as rows") to the dataset A1:J8. For example: The Rows 3 and 5 are not similar (they have different values in most of the cells), BUT from the moment that the name of Column A3 (Cottage) and A5 (Kabylie) and E3 (Cottage) and E5 (Kabylie) are similar, for us are duplicate rows. In A4 we have a similar Value (Cottage) with A3 and A5, but the E4 is not the same, so they are not duplicates.
VS (I): This is the value that we must pick and send or not send to Pick if the criteria has been met.
Pick (J): Here is where we fill or not fill the value (we are taking this value from VS), if the criteria has been met.
Date and Time (G and H): If we have duplicate values (when they exist from the pair of Cheese and Type) we pick from VS the one which is the earliest, as you can see in J4 and we leave empty the other (J5). We have set as duplicates rows 3 and 5 because they have same name in column A and same name in column E, and we have picked the VS from I3, because row 3 has 15:58 time and row 5 has 16:58.
If we have duplicates and they have the same date and time (rows 6, 7, 8 are duplicates with same date and time) we pick the one with the highest value
If there are no duplicated values (like row 2 and row 4) we don't use this criteria. We just pick from VS the value and put it to Pick.