Hi, I'm having a trouble doing text duplicate delete in multiple rows (over 1000)
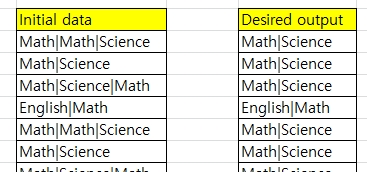
Imagine there is a data set looks like "initial data"
You would find there there are many duplication within the same cell. While it is below the scroll there are cells that has more than 5 math or 3 english.
What i desire to obtain is the get rid of duplicates in each cell as shown in "desired output"
I know this seems like a relatively easier task, but I can't think of a good way to do this.
Text division doesn't really give much value, especially because there are sometimes more than ~3,000 rows sometimes, i can't do this one by one.
Please shed some lights on!
Imagine there is a data set looks like "initial data"
You would find there there are many duplication within the same cell. While it is below the scroll there are cells that has more than 5 math or 3 english.
What i desire to obtain is the get rid of duplicates in each cell as shown in "desired output"
I know this seems like a relatively easier task, but I can't think of a good way to do this.
Text division doesn't really give much value, especially because there are sometimes more than ~3,000 rows sometimes, i can't do this one by one.
Please shed some lights on!
")



